Resources
Data trends. Martech best practices. Hot takes. The strategies and solutions shaking up the market. Get all that and more in MessageGears’ resource library. We’re full of insights on customer engagement, data activation, and personalization.

Blogs
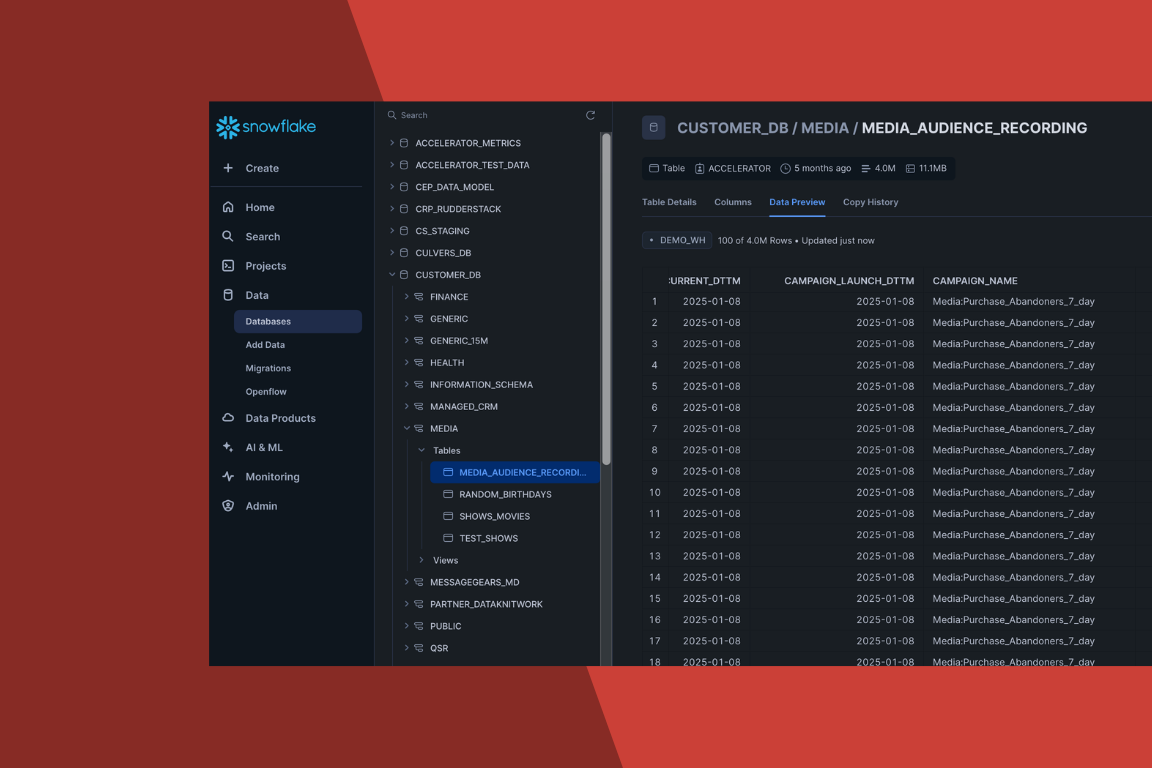
How to reduce data compute costs with smarter querying
Read more about How to reduce data compute costs with smarter querying

How to reduce time-to-market for enterprise campaigns with your data warehouse + MessageGears
Read more about How to reduce time-to-market for enterprise campaigns with your data warehouse + MessageGears

The composable martech playbook: How to cut platform fees 60% by ditching the all-in-one approach
Read more about The composable martech playbook: How to cut platform fees 60% by ditching the all-in-one approach

Why CTOs love MessageGears
Read more about Why CTOs love MessageGears

The future is data-native: 4 trends shaping enterprise customer engagement
Read more about The future is data-native: 4 trends shaping enterprise customer engagement

Elevating your Snowflake modern marketing data stack with native cross-channel execution
Read more about Elevating your Snowflake modern marketing data stack with native cross-channel execution

How MessageGears and Movable Ink help enterprise marketers crush cross-channel personalization
Read more about How MessageGears and Movable Ink help enterprise marketers crush cross-channel personalization
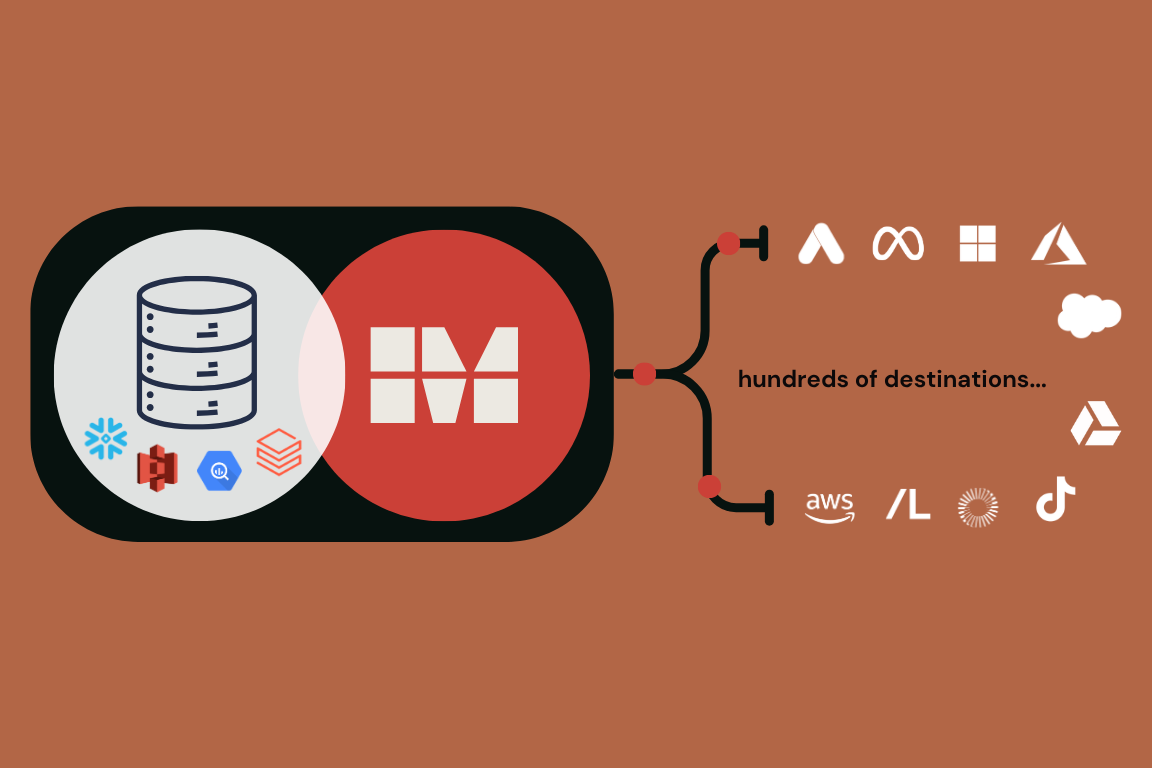
Put your data to work across hundreds of ready-made channel destinations with MessageGears
Read more about Put your data to work across hundreds of ready-made channel destinations with MessageGears
Case studies

Chick-fil-A uses MessageGears to ensure customer privacy
Read more about Chick-fil-A uses MessageGears to ensure customer privacy

How OpenTable reduced campaign production time by 80% with MessageGears
Read more about How OpenTable reduced campaign production time by 80% with MessageGears

MessageGears helps Musictoday send more personalized, dynamic content
Read more about MessageGears helps Musictoday send more personalized, dynamic content

MessageGears is a catalyst for growth at Active Engagement
Read more about MessageGears is a catalyst for growth at Active Engagement

Telefónica uses real-time targeting to drive mobile app activation, engagement, and retention
Read more about Telefónica uses real-time targeting to drive mobile app activation, engagement, and retention

Digicel triples mobile engagement and increases retention by over 50%
Read more about Digicel triples mobile engagement and increases retention by over 50%

Three UK increases revenue by 79% with real-time mobile messaging
Read more about Three UK increases revenue by 79% with real-time mobile messaging

MessageGears and Snowflake help OpenTable take full control of their data
Read more about MessageGears and Snowflake help OpenTable take full control of their data
Guides

12 cost-saving martech tips for enterprise leaders
Read more about 12 cost-saving martech tips for enterprise leaders

Martech buyer’s guide
Read more about Martech buyer’s guide

A retailer’s guide to better data activation in marketing channels
Read more about A retailer’s guide to better data activation in marketing channels

Your guide to better data activation
Read more about Your guide to better data activation

MessageGears consumer engagement report
Read more about MessageGears consumer engagement report

The guide to your Salesforce divorce
Read more about The guide to your Salesforce divorce

The enterprise guide to taking personalization beyond the status quo
Read more about The enterprise guide to taking personalization beyond the status quo

The enterprise perspective on AI and customer engagement
Read more about The enterprise perspective on AI and customer engagement
Events

CRMC
Learn more

Snowflake Summit
Learn more

Databricks Data+AI Summit
Learn more

Inbox Expo
Learn more

Total Retail TECH
Learn more

MediaPost VIP Dinner
Learn more

CONNECT CMO Leadership Summit
Learn more
MediaPost VIP Dinner
Learn more
News
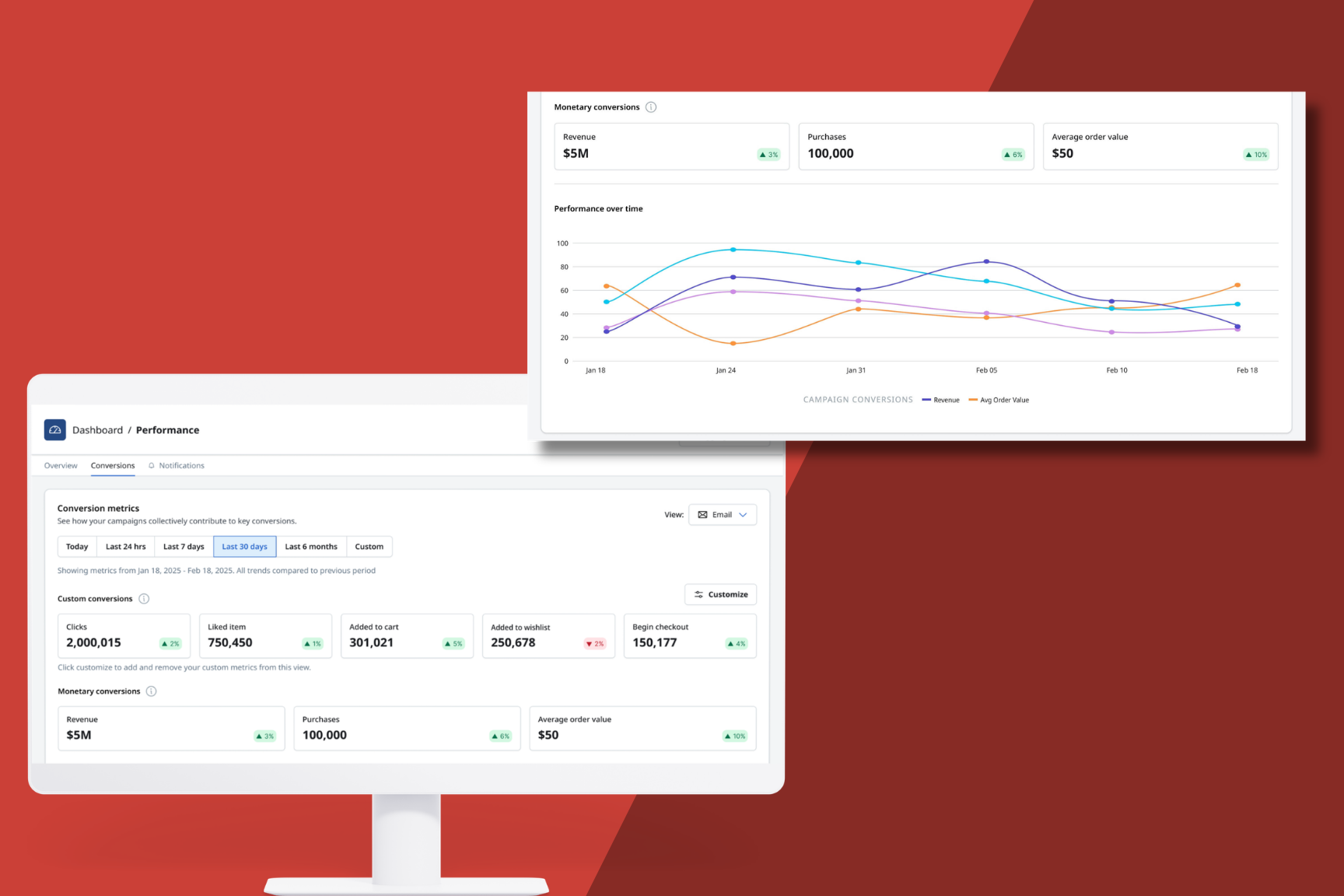
MessageGears delivers warehouse-native revenue tracking for enterprise marketers with new cross-channel conversion analytics
Read more about MessageGears delivers warehouse-native revenue tracking for enterprise marketers with new cross-channel conversion analytics

MessageGears redefines how enterprises manage cross-channel marketing at scale based on how large teams actually work
Read more about MessageGears redefines how enterprises manage cross-channel marketing at scale based on how large teams actually work

New segmentation capabilities from MessageGears give marketers more autonomy and targeting flexibility
Read more about New segmentation capabilities from MessageGears give marketers more autonomy and targeting flexibility

MessageGears Recognized as “One to Watch” in Snowflake’s Modern Marketing Data Stack Report
Read more about MessageGears Recognized as “One to Watch” in Snowflake’s Modern Marketing Data Stack Report
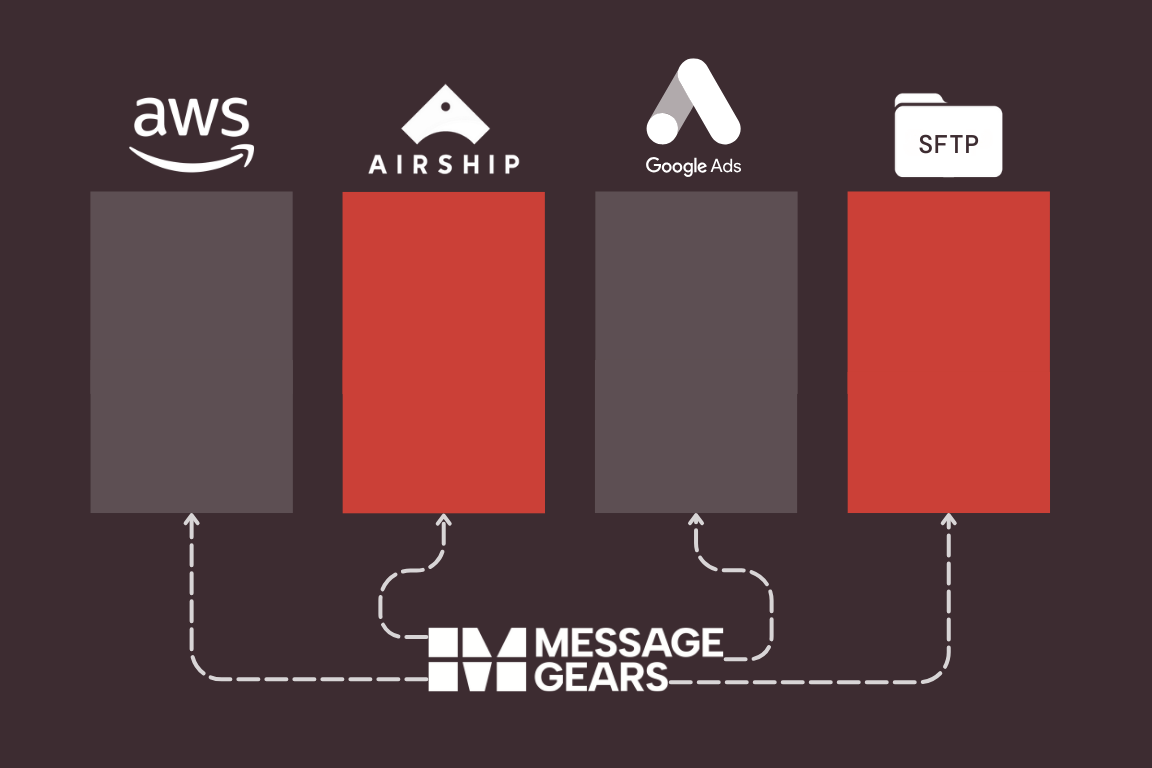
MessageGears introduces multi-destination external campaigns to increase efficiency and reduce compute costs for enterprise brands
Read more about MessageGears introduces multi-destination external campaigns to increase efficiency and reduce compute costs for enterprise brands

MessageGears wins “Best B2C Email Marketing Solution” in 2025 MarTech Breakthrough Awards Program
Read more about MessageGears wins “Best B2C Email Marketing Solution” in 2025 MarTech Breakthrough Awards Program

MessageGears appoints Eugene Yukin to accelerate product innovation and customer-centric growth
Read more about MessageGears appoints Eugene Yukin to accelerate product innovation and customer-centric growth

MessageGears partners with Databricks to power native data activation in enterprise marketing campaigns
Read more about MessageGears partners with Databricks to power native data activation in enterprise marketing campaigns
Webinars

Crawl, walk, run: How to implement a composable CDP
Read more about Crawl, walk, run: How to implement a composable CDP

Understanding composable CDPs
Read more about Understanding composable CDPs

How Chewy creates truly cross-channel campaigns with direct mail
Read more about How Chewy creates truly cross-channel campaigns with direct mail

Choosing the right martech to solve your data problems
Read more about Choosing the right martech to solve your data problems

How GoDaddy went from messy lists to campaign excellence
Read more about How GoDaddy went from messy lists to campaign excellence

Predictive AI trends for customer-obsessed brands
Read more about Predictive AI trends for customer-obsessed brands

7 email re-engagement tips to win back your audience
Read more about 7 email re-engagement tips to win back your audience

Ignite your marketing engine with the power of the data cloud
Read more about Ignite your marketing engine with the power of the data cloud