Blog
ETL vs. reverse ETL: What’s the difference?
Published on April 4, 2025

Sarah Kelly

Data-driven brands have learned the hard way: a warehouse full of data is only as valuable as what you can actually do with it. Snowflake tables teeming with customer behavior? BigQuery models forecasting churn? Impressive – until you realize those insights are trapped in your data cloud while your teams are forced to make calls based on hunches and half-truths.
ETL (extract, transform, load) and reverse ETL exist to fix this. One process feeds your data warehouse with refined, reliable information; the other arms your teams with live intelligence straight into the tools that power everyday action. Together, they form the foundation of a modern data strategy that’s built to make an impact.
Keep reading for a deep dive into both processes, their unique roles, and how to use them in tandem to drive real business outcomes.
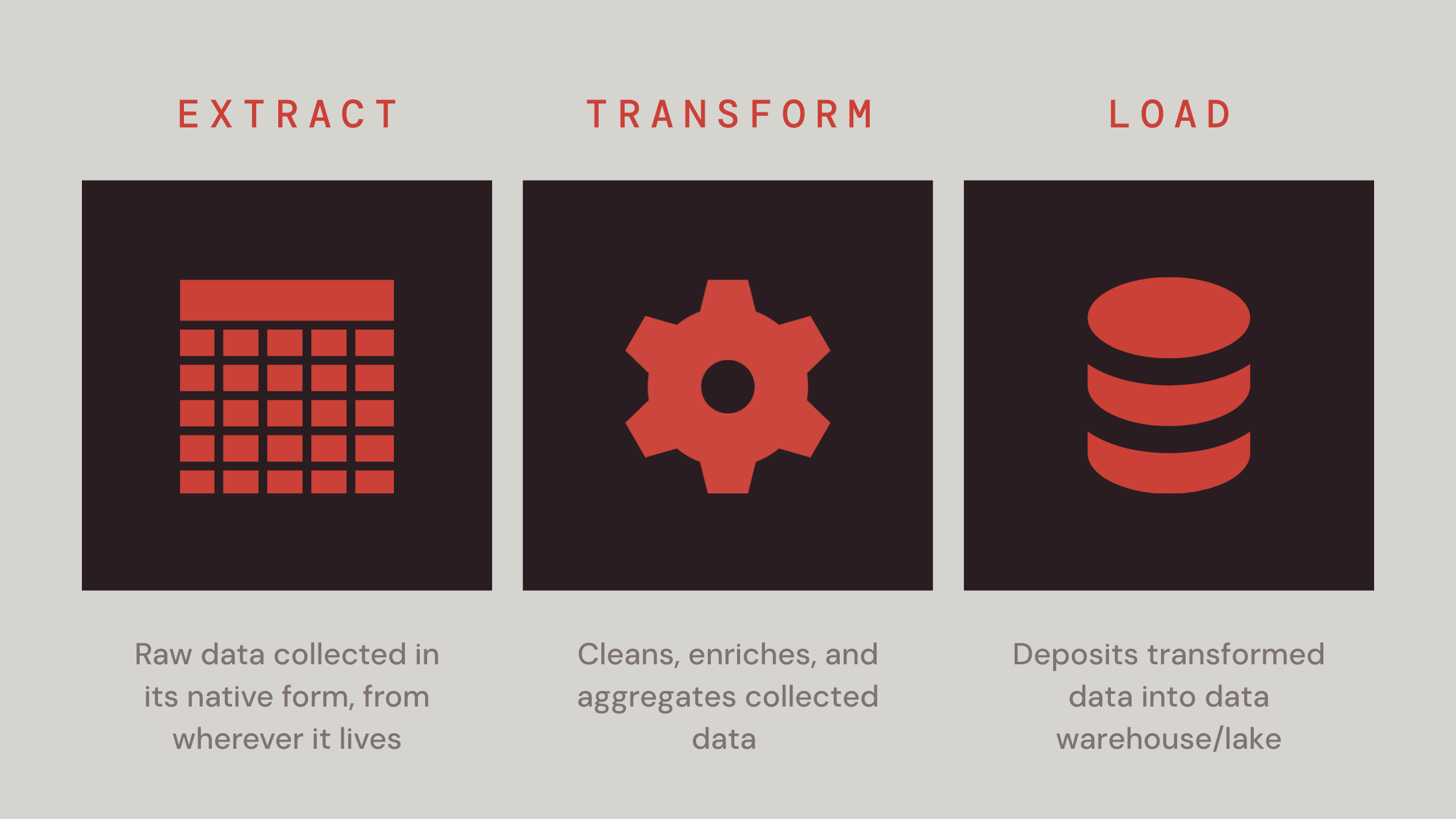
Understanding ETL: The engine behind your data warehouse
A brand’s sprawling data is like an enormous, disorganized library. Every data point is valuable, but without a proper system, finding what you need is nearly impossible. ETL takes raw, unruly data from every nook of your organization, helps you tidy it up within the proper schemas, and shelves it neatly in your data warehouse for easy access. But like a library, its true value depends on how often people check out the books.
Born in an era when brands first began grappling with siloed mainframe systems, ETL became the go-to solution for taming chaotic data and converting it into something usable – a unified dataset ready for deep analysis and strategic insight. Without it, you can’t build clean dashboards, train ML models, or even trust your metrics.
Extract: Gathering data from every corner
ETL begins by pulling data from wherever it lives: databases, APIs, SaaS tools, legacy systems, and even rogue spreadsheets. The goal at the extraction phase is raw data collection in its native format, whether that’s JSON, CSV, SQL, or something else entirely.
Transform: Fixing what’s broken
Raw data doesn’t come analysis-ready. It’s full of inconsistencies – rate-limited APIs, inconsistent pagination, and schema changes mid-ingestion (looking at you, Salesforce).
Transformation is where you clean up these issues:
- Clean: Scrub duplicate records (like that extra “Customer_ID_123” from a retired API call), flag outliers (a “user_age” value of “150”), and standardize inconsistent schemas (merge “Jan 1 2025,” “01/01/2025,” and “2025-01-01” into one uniform format).
- Enrich: Join disparate datasets to add depth (link transactions to support tickets), add calculated fields (LTV, churn risk), and attribute revenue metrics.
- Aggregate: Compress granular user events into coherent trends (convert 10 million rows of hourly website clicks into daily traffic summaries).
Tools like dbt and Informatica codify these rules, so “Boston,” “BOS,” and “bos” don’t end up as three separate entries in your regional sales reports.
Load: Building a unified repository
The final phase of ETL deposits polished, transformed data into your centralized data lake or data warehouse (e.g. Snowflake, BigQuery, Redshift, or Databricks). Here, your data becomes query-ready, primed for analytics, machine learning, and activation.
Loading can happen in one of two ways:
- Full loads: A complete overhaul where you replace all existing data with fresh inputs.
- Incremental loads: A more agile method where only new or modified records are added – ideal for high-velocity environments. For example, a logistics company might opt for incremental loading to track real-time delivery performance without reprocessing the entire dataset every time.
Understanding reverse ETL: Bringing data to life
While ETL lays the foundation, reverse ETL is what breathes life into your data. Instead of letting rich intelligence gather dust in dashboards, reverse ETL delivers them straight to the tools your teams live in (CRMs, engagement tools, ad platforms, you name it) so they can act on it – in context – right from where they work. No more waiting for custom API scripts or delayed CSV exports.
Data selection: Zeroing in on what matters
Reverse ETL starts by identifying the exact slices of data your teams need. Whether it’s lead scores indicating who’s ready to buy, churn risks flagging potential cancellations, product usage trends revealing underused features, or customer LTV metrics that spotlight upsell opportunities, reverse ETL zeroes in on precise data points so your teams aren’t bogged down by irrelevant details.
Mapping: Speaking the right language
Your data needs to be fluent in the language of its destination. This involves mapping fields from your warehouse to corresponding fields in your tools. For example, a “lead_score” in Snowflake might need to map to a custom “Priority” field in Salesforce. Or a “trial_expiration_date” in BigQuery syncs with a “Renewal Date” in HubSpot. These light transformations make sure data is fully compatible with the destination app’s schema and functionality.
Sync execution: Real-time, on-demand updates
While ETL runs on scheduled batches, reverse ETL operates on triggers. As soon as a metric changes – say, a customer’s status jumps from “lead” to “opportunity” or their churn risk spikes from 40% to 60% – reverse ETL immediately pushes that update to your CRM or marketing platform. This agility means teams can act on live insights, engaging customers with time-sensitive campaigns and providing proactive support to nip churn in the bud.
Take an e-commerce brand that calculates customer LTV in its data warehouse. Reverse ETL can automatically push those scores into its audience building tool, so marketing teams can segment customers into VIP, at-risk, or dormant cohorts and trigger targeted campaigns on the fly.
Activation: Turning numbers into action
Once actionable data lands in the hands of your frontline teams, it ceases to be just numbers in a dashboard and becomes an active driver of decisions. Sales reps see real-time lead scores, support teams get alerts about high-risk accounts, and marketing platforms update audience segments based on live behavior – all without waiting on IT for “just one more CSV export.”
Too many brands drown in insights that never leave the data cloud. Reverse ETL fixes this by pushing live data into the trenches. ETL tells you what happened. Reverse ETL tells you what to do next, picking up the baton and transforming your warehouse from a passive archive into an active engine – without the extra baggage of copied data and soaring storage costs.
Key differences between ETL and reverse ETL
While ETL and reverse ETL are two sides of the same coin, they serve very different purposes in the data lifecycle. Here’s where they split paths:
Direction of data flow
ETL: Funnels raw data inward, consolidating diverse sources into one coherent repository.
Example: A skincare brand ingests Shopify orders, TikTok Ads clickstreams, and Zendesk support tickets into BigQuery. ETL unifies these streams, linking customer emails to order histories and ad interactions.
Reverse ETL: Propels data outward, taking enriched data from the warehouse and delivering it to the tools that drive customer interactions.
Example: That same brand syncs real-time product affinity scores to its email platform, triggering personalized campaigns like “Loved our vitamin C serum? Check out our new retinol cream.”
Target users
ETL: Caters primarily to data engineers and analysts who live in dashboards and SQL editors. Its outputs – clean datasets, dashboards, BI reports – are designed for deep dives into historical trends and long-term strategy.
Example: A streaming service uses ETL to aggregate binge-watching patterns in Snowflake, analyzing which shows correlate with subscription loyalty.
Reverse ETL: Serves operational teams – marketing, sales, support, and product – who need immediate, actionable data embedded in their everyday tools.
Example: The same brand pushes “abandoned watchlist” alerts to its mobile messaging platform, prompting users to continue watching Stranger Things with a timely push notification.
Transformation complexity
ETL: Engages in deep transformation – standardizing inconsistent formats and enriching datasets for analytical integrity.
Example: A retailer transforms raw POS data, weather feeds, and Google Trends signals to predict holiday demand spikes.
Reverse ETL: Applies lightweight, destination-specific mapping and minor tweaks so data is immediately ready for action.
Example: A food delivery app monitors real-time weather data in its data warehouse. When a snowstorm hits Chicago, reverse ETL pushes “delivery delay” alerts to the app, offering users a $5 credit to wait or cancel penalty-free – reducing support tickets and maintaining customer satisfaction.
Precision vs. speed
ETL: Prioritizes accuracy and historical consistency, operating on scheduled batch processes.
Example: Amazon’s nightly ETL run reconciles returns, refunds, and inventory changes to update “profit per SKU” metrics.
Reverse ETL: Prioritizes speed and agility, triggering updates to operational systems as soon as data shifts.
Example: When a customer abandons their cart at 2:05 PM, reverse ETL triggers a “10% off if you complete now” nudge from your SMS platform by 2:07 PM – no waiting for the next batch cycle.
When to use ETL: The heavy lifter for data integrity
ETL is indispensable when accuracy, governance, and historical context matter most. Here’s where it shines:
Building a single source of truth
For compliance, auditing, and company-wide reporting, you need one definitive version of reality. ETL aggregates data from siloed systems, disjointed marketing platforms, and legacy databases into one governed warehouse – putting an end to the version conflicts between finance’s spreadsheets and marketing’s dashboards.
Example: A fast-fashion retailer uses ETL to combine sales data from hundreds of stores – each with its own tax codes, SKU formats, and time zones – into a unified dataset. This way, everyone from the CFO in Singapore to the CMO in LA is debating the same numbers, not different narratives.
Customer 360 analytics
Unified customer profiles sound great – until you’re trying to merge data from six CRMs, three e-commerce platforms, and a stream of mobile app events. ETL stitches this chaos into a coherent timeline, connecting web clicks to Shopify orders, support tickets to loyalty programs, and ad interactions to Salesforce leads.
Example: Spotify ingests data from mobile app streams, web player sessions, and family plan signups. ETL links anonymous “Guest” listens to logged-in accounts when users subscribe, creating a complete journey: a free user who streamed Guns n’ Roses 50 times and then signed up for a paid subscription receives tailored content recommendations from the moment they become a paying customer.
Accuracy and compliance
In industries where every data point is subject to strict regulations, ETL enforces rigorous rules – masking PII, enforcing lineage tracking, and validating formats – so you can confidently trace any changes back to its source.
Example: A healthcare provider harmonizes patient data across EHR (electronic health record) systems to meet HIPAA’s ironclad rules. When auditors ask, “Why did this patient record change on 4/12?” you can trace the change back to a specific schema update – no loose ends.
Legacy system integration
Many enterprise brands grapple with a patchwork of outdated systems that refuse to play nice with modern tools. ETL’s heavy-lifting capabilities can migrate decades of messy data from on-prem databases to your modern data warehouse – turning COBOL-era relics into cloud-ready data.
Example: Say Walmart migrates decades of in-store purchase data from IBM DB2 to Snowflake. ETL converts mainframe-era product codes to modern SKUs, preserves legacy loyalty program IDs, and maps archaic tax formats to modern e-commerce rules. It’s not exactly glamorous, but without this consolidation, Walmart’s $10B+ online business would crumble under the weight of mismatched data.
When to use reverse ETL: Driving immediate impact
In fast-paced sectors like retail and e-commerce, waiting for batch updates or manual exports can mean losing ground to competitors that act faster. When every minute counts, reverse ETL is the tool that turns your warehouse into a launchpad for real-time action.
Here’s where it delivers tangible value:
Instant campaign activation
Customers expect brands to be intuitive – read their minds almost. Hesitation – whether at the checkout page or during a product browse – is a signal, not a dead end. Reverse ETL operationalizes these micro-moments, whether it’s cart abandonment, session duration, or click heatmaps, so campaigns react to real-time action, not last night’s data dump.
Example: A skincare brand tracks users who view luxury product pages without checking out. Reverse ETL pushes these profiles to Meta Ads, triggering dynamic ads with a “15% off La Mer” offer ready to serve the customer when they next check their feed.
Proactive churn prevention
Customer loyalty hinges on anticipation, not reaction. Reverse ETL turns your tools into early-warning centers by syncing risk scores and behavioral cues into your engagement tools, triggering proactive outreach before a customer slips away.
Example: A customer’s login frequency drops 40% week-over-week. Reverse ETL updates their profile with a “churn risk” tag, prompting a personalized email urging them to re-engage: “Missing your playlists? Here’s 3 new albums you’ll love.”
Ending analysis paralysis
All the insights in the world are useless if they never leave your data warehouse. Reverse ETL closes the loop between data discovery and action. Instead of waiting on IT to churn out CSV exports or engineers to build custom API pipelines, reverse ETL deploys warehouse-rich insights where it’s needed, when it’s needed.
Example: A fitness brand identifies users who haven’t logged a workout in 30 days. Reverse ETL pushes those IDs to its mobile messaging platform, surfacing a “Come back for 2K bonus points” push notification during prime workout hours.
Automated decision making
Brands operating at scale can’t afford process bottlenecks. Reverse ETL removes manual workflows from the loop by automating high-volume, low-risk actions directly from your data cloud – without unnecessary complexity.
Example: A food delivery brand uses reverse ETL to monitor driver behavior. If a driver declines three consecutive orders, the system automatically adjusts their queue priority, favoring drivers with 95%+ acceptance rates during peak hours.
The need for real-time speed
Reverse ETL thrives on CDC (change data capture), feeding live behavioral data back into your product ecosystems for dynamic experiences that adapt to every user. Adjust UI elements, surface context-aware promotions, and tailor content recommendations – all because you can tap into your live warehouse data to shape 1:1 experiences.
Example: A streaming service syncs real-time viewing habits to its recommendation engine. As soon as a free-tier user hits an API rate limit, reverse ETL triggers an in-app upsell featuring content aligned with their tastes: “Upgrade to Premium for unlimited access to Harlan Coben thrillers.”
Complementary engines for your data pipelines
For decades, ETL has been the standard for data integration, quietly funneling information from disparate sources into centralized repositories for in-depth analysis. But even the richest data loses its luster if it’s confined. Reverse ETL emerged to solve this problem, converting structured insights into actionable intelligence that powers every part of your org.
ETL builds your history. Reverse ETL writes your future. Together, they form a continuous cycle: raw data becomes insights, insights drive actions, and those actions generate fresh data – feeding back into the cycle for further analysis and innovation. No more hoarding data in dark warehouses. Instead, you give your teams exactly what they need to turn warm leads into closed deals, dormant users into loyal advocates, and fleeting trends into long-lasting impact.
Reverse ETL with MessageGears: The modern data activator
MessageGears is designed for modern enterprise teams who need to operationalize data now – without duplicating datasets, waiting for hourly syncs, or asking engineering for help.
By connecting directly to your data warehouse, MessageGears bypasses the need for costly third-party data storage and the associated compute expenses. This means your budgets (and resources) stay lean while gaining instant access to the insights your teams need to fuel real-time decision-making:
- Direct data access: Bypass API limits and staging tables by tapping directly into your data warehouse’s raw potential.
- Self-serve audience segmentation: Equip your marketing teams with the autonomy to build dynamic audience segments on the fly – no SQL = no IT roadblocks.
- Real-time activation: Trigger campaigns the moment behavior shifts. No more waiting for batch jobs to catch up with your insights.
- Unified governance: Leverage your live data with confidence, knowing that governance, compliance, and security are baked in from the start.
Ready to move beyond static dashboards, keep your data where it belongs, and slash unnecessary compute cycles? Embrace a robust reverse ETL process with MessageGears and deliver the actionable insights your teams crave, directly from your modern data warehouse – no data copies, no risky moves, no delays.